Chapitre 3 Bien commencer
3.1 Créer un projet sous Rstudio pour vous permettre de recenser vos travaux.
Pourquoi travailler avec les projets Rstudio plutôt que les scripts R ?
- Cela permet la portabilité : le répertoire de travail par défaut d’un projet est le répertoire où est ce projet. Si vous transmettez celui-ci à un collègue, le fait de lancer un programme ne dépend pas de l’arborescence de votre machine.
Fini les
setwd("chemin/qui/marche/uniquement/sur/mon/poste")!
- Toujours sur la portabilité, un projet peut être utilisé avec un outil comme
packratqui va vous intégrer en interne au projet l’ensemble des packages nécessaires au projet. Cela permet donc à votre collègue à qui vous passez votre projet de ne pas avoir à les installer et, surtout, si vous mettez à jour votre environnement R, votre projet restera toujours avec les versions des packages avec lesquelles vous avez fait tourner votre projet à l’époque. Cela évite d’avoir à subir les effets d’une mise à jour importante d’un package qui casserait votre code.
Pour activer packrat sur un projet, aller dans Tools/Project Options->Packrat
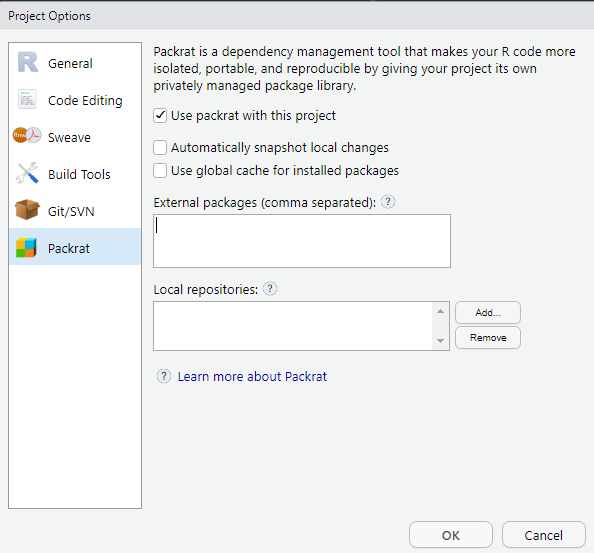
Cela permet de se forcer à travailler en mode projet : on intègre à un seul endroit tout ce qui est lié à un projet : données brutes, données retravaillées, scripts, illustrations, documentations, publications… et donc y compris les packages avec
packrat.On peut travailler sur plusieurs projets en même temps, Rstudio ouvre autant de sessions que de projets dans ce cas.
Les projets Rstudio intègrent une interface avec les outils de gestion de version Git et SVN. Cela veut dire que vous pouvez versionniser votre projet et l’héberger simplement comme répertoire sur des plateformes de gestion de code telle que Github ou Gitlab.
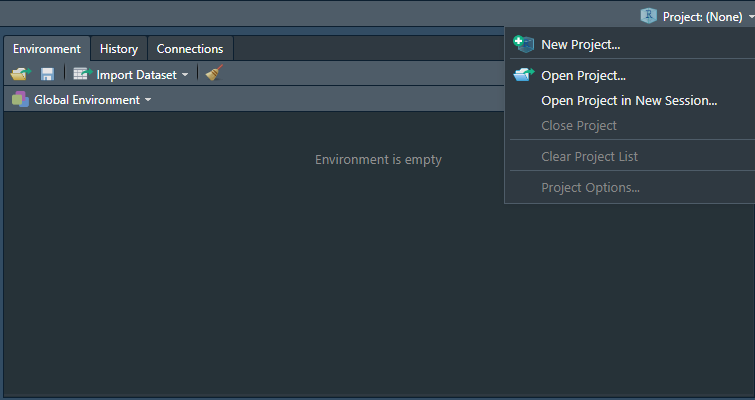
Pour créer un projet :
- Cliquez sur Project en haut à droite puis New Project.
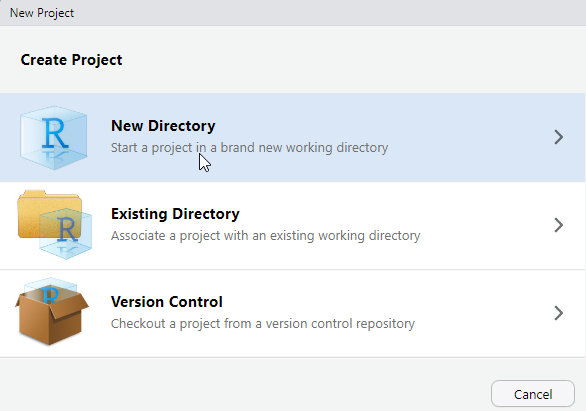
- Cliquez sur New Directory.
3.2 Intégrer vos données
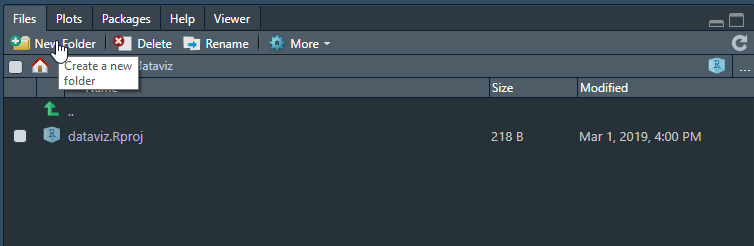
Une bonne pratique est de créer un sous répertoire /data pour stocker les données sur lesquelles vous aurez à travailler.
Vous pouvez le faire depuis l’explorateur de fichier de votre système d’exploitation ou directement à partir de l’explorateur de fichier de RStudio.
Cela marche bien quand on a un seul type de données, mais en général on va avoir à travailler sur des données brutes que l’on va retravailler ensuite et vouloir stocker à part. Si par la suite vous souhaitez avoir des exemples de bonnes pratiques sur comment structurer vos données, vous pouvez vous référer au chapitre data du livre d’Hadley Wickham sur la construction de packages R (tout package R étant aussi un projet !).
3.3 Créer votre arborescence de projet
- Créer un répertoire
/srcou vous mettrez vos scripts R. - Créer un répertoire
/figuresou vous mettrez vos illustrations issues de R.
3.4 Activer les packages nécessaires
Commencer par rajouter un script dans le répertoire /src à votre projet qui commencera par :
activer l’ensemble des packages nécessaires
charger les données dont vous aurez besoin.
library (tidyverse)
library (FactoMineR)
library (factoextra)
library (GGally)
library (ggExtra)
library (data.table)
library (DT)
library (grid)
geoidd <- read.csv2 (file = "data/ACP.csv", header = T, encoding = "latin1")
taille <- read.csv2 ("data/Effet_taille.csv", header = TRUE,
encoding = "latin1")
data (iris)
data (hobbies)3.5 Bien structurer ses projets data
Plusieurs documents peuvent vous inspirer sur la structuration de vos projets data par la suite.
En voici quelques uns :
- https://github.com/pavopax/new-project-template
- https://nicercode.github.io/blog/2013-04-05-projects/
- https://www.inwt-statistics.com/read-blog/a-meaningful-file-structure-for-r-projects.html
- http://projecttemplate.net/architecture.html
À partir du moment où quelques grands principes sont respectés (un répertoire pour les données brutes en lecture seule par exemple), le reste est surtout une question d’attirance plus forte pour l’une ou l’autre solution. L’important est de vous tenir ensuite à conserver toujours la même arborescence dans vos projets afin de vous y retrouver plus simplement.