Chapitre 4 L’ACP
4.1 Principe de l’ACP
4.1.1 Type de données
On dispose d’un tableau de \(n\) lignes et \(p\) colonnes actives qui sont uniquement des variables quantitatives (au sens large, des binaires codées 0/1 ou des variables ordinales passent).
4.1.2 Objectifs
Une ACP peut permettre de :
- Résumer l’information.
- Identifier les corrélations entre variables actives.
- Identifier les proximités entre les individus.
4.1.3 Méthode
L’ACP va déterminer, dans un espace à \(p\) dimensions (sous l’hypothèse qu’aucune des variables n’est une combinaison linéaire des autres), l’axe le long duquel les points représentant les individus sont les plus “étalés”. Cet axe \(F_1\) est une combinaison linéaire des variables de départ.
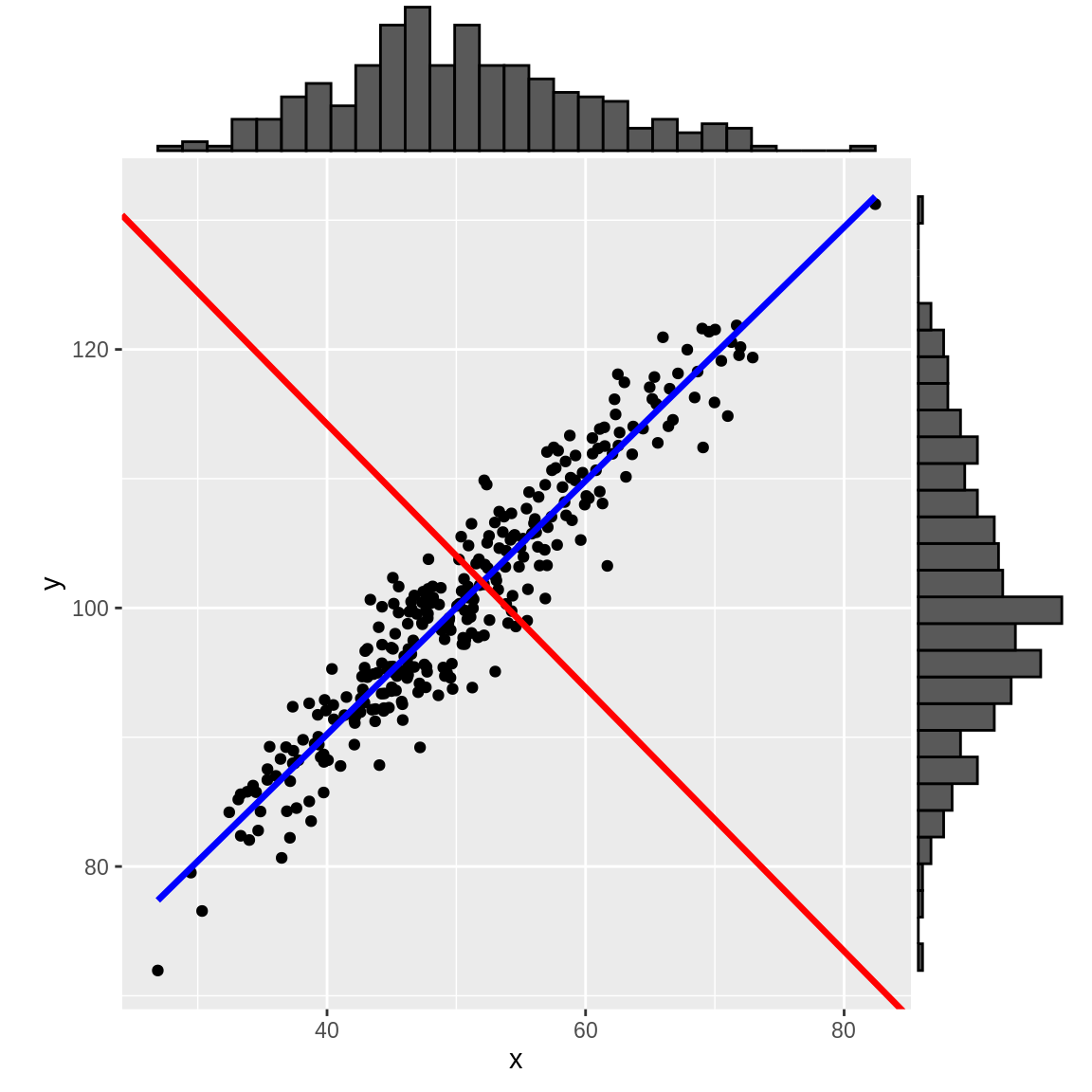
Dans l’exemple graphique ci-dessous et en 2D, la dispersion des points est essentiellement le long de l’axe bleu. L’axe rouge est orthogonal au bleu. Dans le repère \((O, x, y)\), la variance est à peu près équivalente sur \(x\) et sur \(y\). A l’inverse, dans le repère constitué des axes de couleur, la variance est portée essentiellement sur le bleu tandis que le rouge ne porte qu’une faible partie de l’inertie du nuage de point. En gros, l’axe bleu est la première composante principale, généralement notée \(PC_1\) ou \(F_1\), et le rouge \(PC_2\) ou \(F_2\).
Ce changement de repère peut être visualisé ainsi :
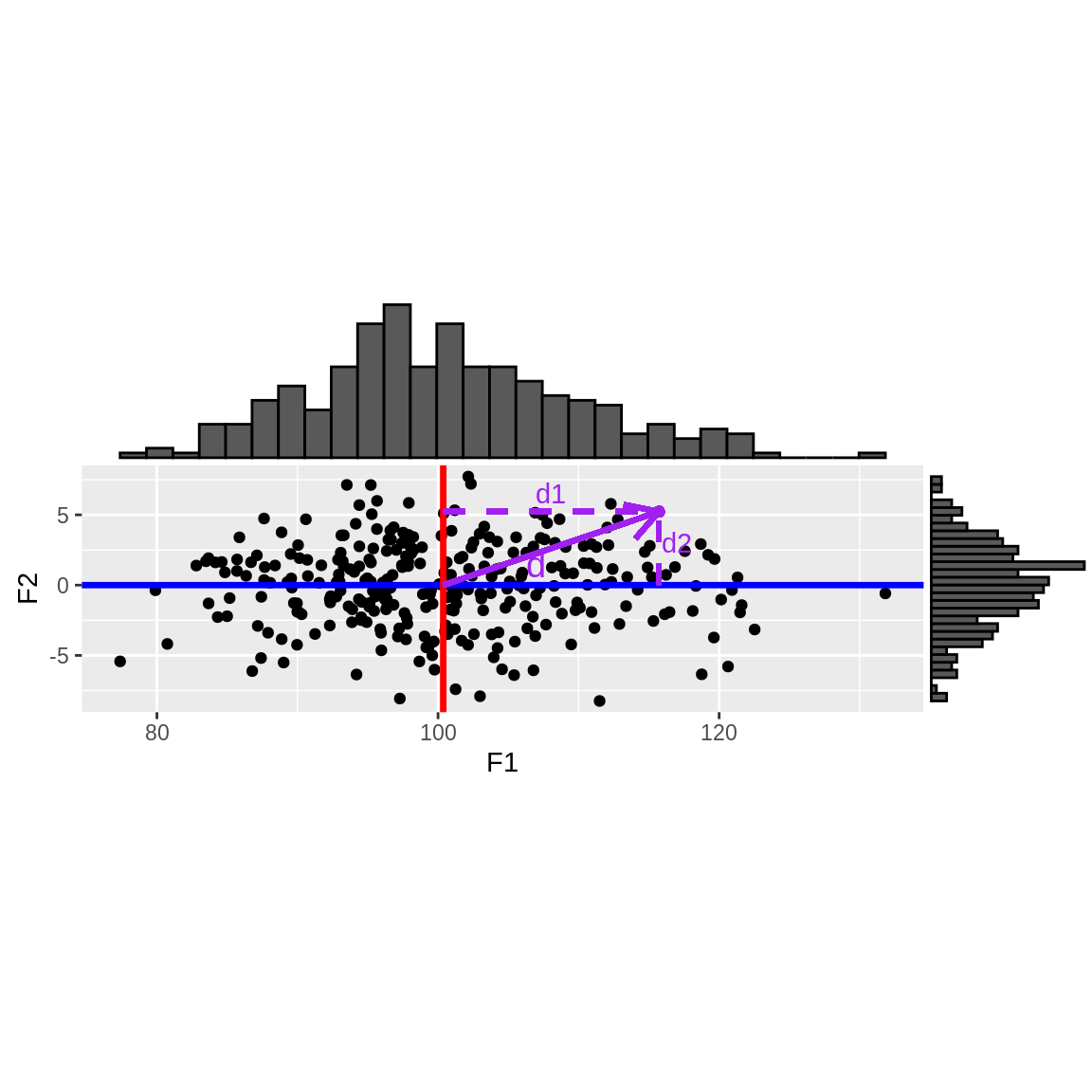
Dans ce nouveau repère, l’essentiel de la dispersion des points peut être “résumé” par leur position sur \(F_1\).
La variance du nuage de points caractérise sa dispersion. C’est la moyenne, sur l’ensemble des points, des carrés des distances au centre d’inertie du nuage. D’après le théorème de Pythagore, elle peut être décomposée en composantes orthogonales car \(d^2=d_1^2+d_2^2\).
\(V={\frac 1n}\sum _{{i=1}}^{n}(d_{i})^{2}\\ ={\frac 1n}\sum _{{i=1}}^{n}[(d_{1i})^{2}+(d_{2i})^{2}]\\ ={\frac 1n}\sum _{{i=1}}^{n}(d_{1i})^{2}+{\frac 1n}\sum _{{i=1}}^{n}(d_{2i})^{2}\\ =V_1+V_2\)
Lors du changement de repère, on a conservé la variance totale du nuage de points, mais au lieu d’être répartie également entre les variables \(x\) et \(y\), elle est concentrée sur \(F_1\).
Pour un nombre de variables \(p>2\), on généralise. \(F_1\) est l’axe qui porte le plus d’inertie, puis \(F_2\) est, dans le sous-espace orthogonal à \(F_1\), celui qui porte le plus d’inertie, et ainsi de suite. Le nombre total d’axes est \(p\) (sauf à avoir des variables qui sont des combinaisons linéaires les unes des autres, ce qui intervient par exemple quand la somme des colonnes fait 100%).
Faire une ACP revient donc à effectuer un changement de repère. Dans notre dataframe de départ, chaque colonne peut être vue comme une coordonnée de chacun des individus. Ce n’est pas un repère orthonormé car les variables sont plus ou moins corrélées les unes aux autres. Quand on représente le nuage de points dans le repère \((O, F_1, F_2)\), les axes sont indépendants (corrélation nulle).
En d’autres termes, l’ACP consiste à construire un nouvel espace vectoriel orthonormé (les variables construites sont non-corrélées 2 à 2) de même dimension que l’espace de départ, mais où l’inertie sera concentrée sur les premiers axes factoriels. Mathématiquement, cela conduit à diagonaliser la matrice de variance-covariance ; les valeurs propres correspondent à la part de l’inertie totale portée par chaque axe factoriel.
4.1.4 Centrer - réduire ?
Si l’on a des variables de dispersion (variance) très différentes, ou d’unités différentes, en général il fait centrer (retrancher la moyenne) et réduire (diviser par l’écart-type) chacune des variables avant d’effectuer l’ACP. Dans ce cas chacune des variables a la même importance (variance de 1) \(\Rightarrow\) l’inertie du nuage vaut \(p\).
C’est l’option par défaut dans la fonction PCA de FactoMineR (scale.unit = TRUE), qui réalise donc une ACP dite “normée”.
Note : Les espaces des variables et des individus ne sont pas les mêmes en ACP \(\Rightarrow\) on ne peut pas les représenter simultanément. Dans les autres analyses, on le peut.
4.2 L’ACP avec FactoMiner
4.2.2 Exemple
4.2.2.1 Données utilisées
- Données communales téléchargées sur Géoïdd et converties en format .csv (attention aux valeurs N/A ou autres dans le fichier Excel qui peuvent parasiter l’importation de données).
- Les individus statistiques sont les communes (lignes) et les variables (colonnes) différents indicateurs décrivant ces communes.
- Objectif : voir quels indicateurs différencient le plus les communes, et quelles sont les communes qui s’écartent le plus de la moyenne.
- Utilisation de variables qualitatives supplémentaires pour compléter la description (présence d’un agenda21 et d’un PPRN).
4.2.2.2 Importation et exploration rapide
Les données sont dans le fichier ACP.csv.
Le fait d’affecter les code géographiques comme row.names du dataframe permet de mieux identifier les individus sur les graphiques (et les sorties) par la suite.
ATTENTION, certaines fonctions du package dplyr du tidyverse, comme mutate, suppriment les noms des lignes.
dat <- geoidd %>%
select (-code, -communes)
row.names (dat) <- geoidd$code
dat$agd21 <- as.factor (paste ("Agenda21 ", (dat$part_agenda21 > 0) + 0))
dat <- dat %>%
select (- part_agenda21) %>%
na.omit()Matrice de corrélations sur les variables quantitatives :
## Densite tx_emploi part_artif part_proprio ind_vieill
## Densite 1.00 0.09 0.68 -0.35 -0.06
## tx_emploi 0.09 1.00 0.25 -0.34 0.07
## part_artif 0.68 0.25 1.00 -0.48 -0.10
## part_proprio -0.35 -0.34 -0.48 1.00 0.03
## ind_vieill -0.06 0.07 -0.10 0.03 1.00Tableau croisé sur les variables qualitatives :
##
## 0 - Absence de PPRN 1 - PPRN prescrit 2 - PPRN approuvé
## Agenda21 0 21768 2321 8306
## Agenda21 1 2916 136 1063
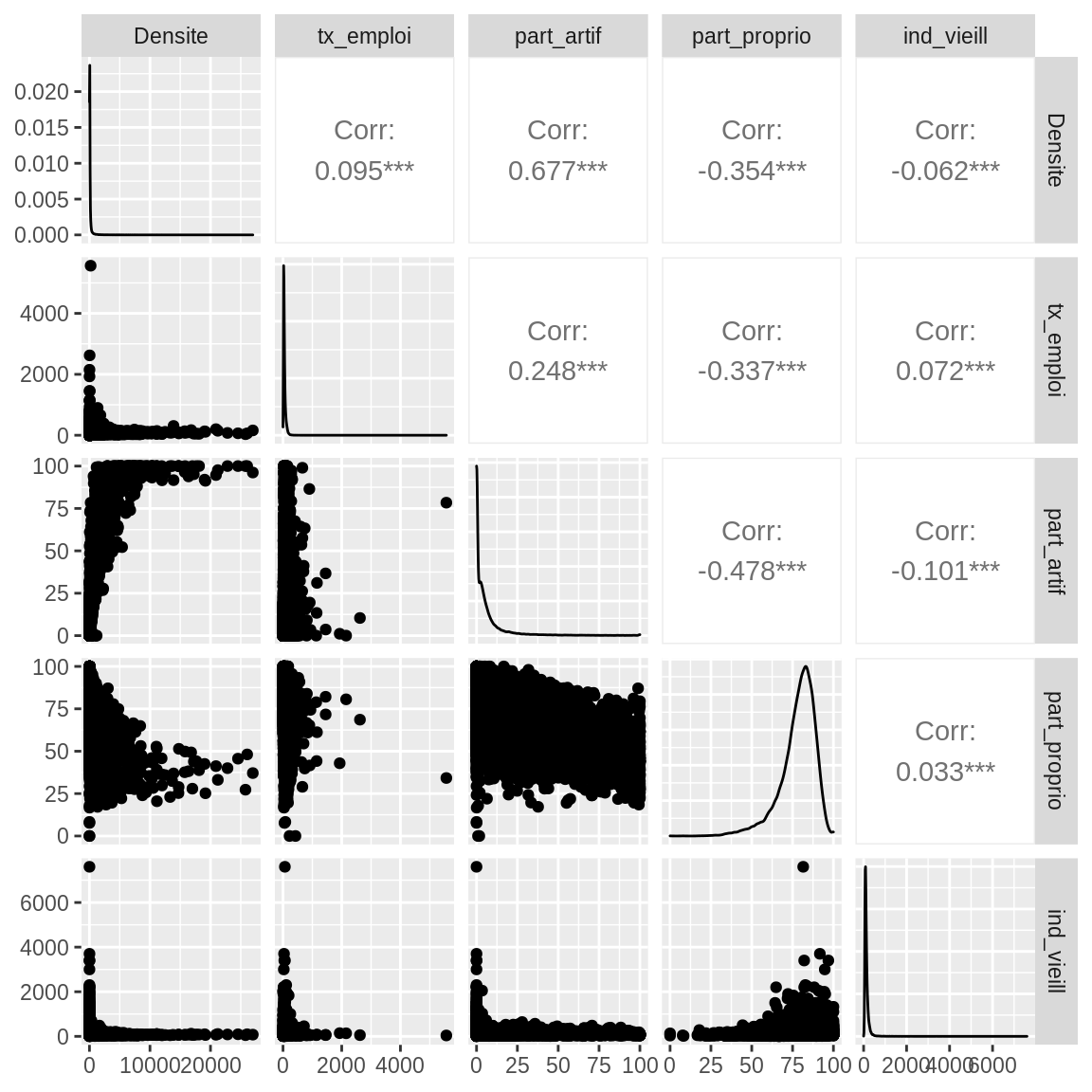
## Agenda21 NA 0 0 0On remarque dans un premier temps que les corrélations ne sont pas très élevées entre les variables. La corrélation la plus élevée est celle entre la densité de population et la part de terres artificialisées. Le lien entre les variables PPRN et Agenda21 est peu évident avec le tableau de fréquences.
On peut utiliser les fonctions vues dans le module 3 pour explorer les données :
4.2.2.3 Réaliser l’ACP
Pour voir l’aide : ?PCA.
On voit que par défaut les variables sont centrées - réduites et que les valeurs manquantes sont remplacées par la moyenne de la colonne à laquelle elles appartiennent. Il est important de se questionner sur la pertinence de ces options “par défaut”.
Réalisation de l’ACP :
La fonction PCA retourne un objet de type liste (de liste), qui contient toutes les informations nécessaires à l’interprétation des résultats et leur utilisation : on y retrouve notamment, pour les individus et pour les variables, sur chacun des axes :
- Les coordonnées factorielles (coord).
- La qualité de représentation (cos2) sur chaque axe.
- La contribution à la formation de l’axe (c’est à dire la part de variance de l’axe portée par l’individu / la variable).
Pour accéder aux résultats de l’ACP, on peut voir les objets contenus dans cette liste :
## [1] "eig" "var" "ind" "svd" "quali.sup" "call"Chacun de ces sous-objets (par exemple acp$ind) contient à son tour des éléments :
## [1] "coord" "cos2" "contrib" "dist"Pour tout visualiser d’un coup, on peut utiliser la fonction str :
L’élément eig donne les valeurs propres de la matrice de variance-covariance, autrement dit la part d’inertie portée par chacun des axes factoriels. Pour accéder aux coordonnées factorielles des individus, on apppelle l’élément coord de l’élément ind de l’objet acp.
Contributions des individus à chacun des axes :
Recherche des individus qui contribuent le plus aux axes. Pas mal de fonctions du tidyverse font disparaître les noms des lignes \(\Rightarrow\) on les stocke provisoirement dans une variable avec la fonction rownames_to_column() puis on les ré-attribue avec la fonction réciproque column_to_rownames()
acp$ind$contrib %>%
round (digits = 5) %>%
as.data.frame () %>%
rownames_to_column (var = 'Commune') %>%
mutate (somme = rowSums (select(., starts_with ("Dim")))) %>%
filter (somme > 0.2) %>%
column_to_rownames (var = 'Commune') %>%
datatable ()En ordonnant le tableau selon les différentes composantes principales, on peut identifier les communes qui contribuent le plus à chacun des axes.
On peut également utiliser les fonctions génériques summary et plot (ou plot.PCA ; cf. ?plot.PCA) pour aborder ce nouvel objet.
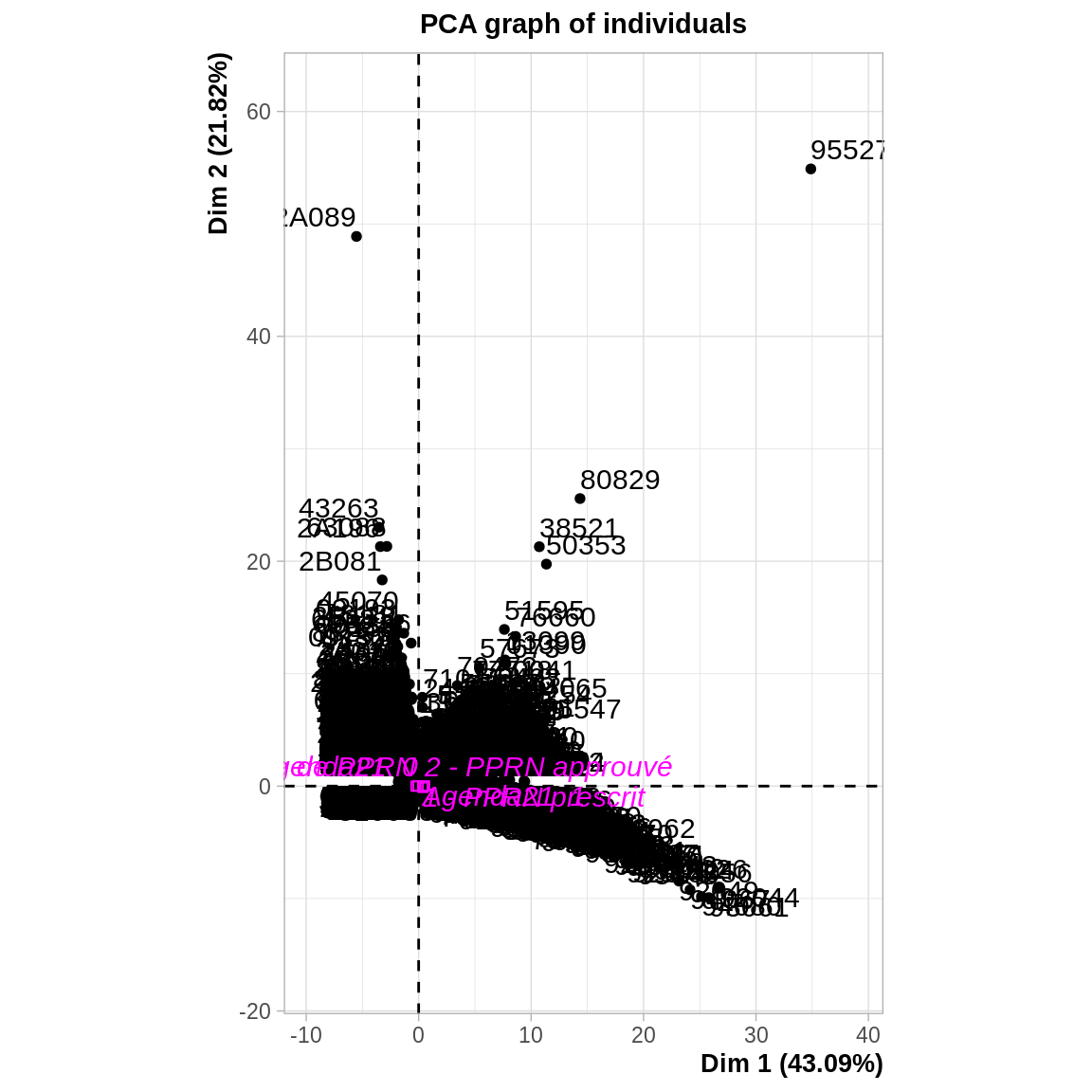
4.2.2.4 Nombre d’axes à retenir
On accède aux valeurs propres par l’objet acp$eig :
## eigenvalue percentage of variance cumulative percentage of variance
## comp 1 2.1546177 43.092354 43.09235
## comp 2 1.0908956 21.817913 64.91027
## comp 3 0.8865747 17.731493 82.64176
## comp 4 0.5718572 11.437144 94.07890
## comp 5 0.2960548 5.921095 100.00000On peut représenter graphiquement les valeurs propres (« éboulis » des valeurs propres).
eig <- as.data.frame (acp$eig)
mm <- mean (eig$`percentage of variance`) / 100
ggplot (eig, aes (x = 1:nrow(eig), weight = `percentage of variance`)) +
geom_bar (fill = "grey20") +
ggtitle ("Valeurs propres") +
theme (axis.title.x = element_blank(), axis.title.y = element_blank()) +
scale_y_continuous (labels = function(x) paste0(x, "%")) +
geom_hline (yintercept = 20, colour="red", linetype="dashed") +
coord_flip ()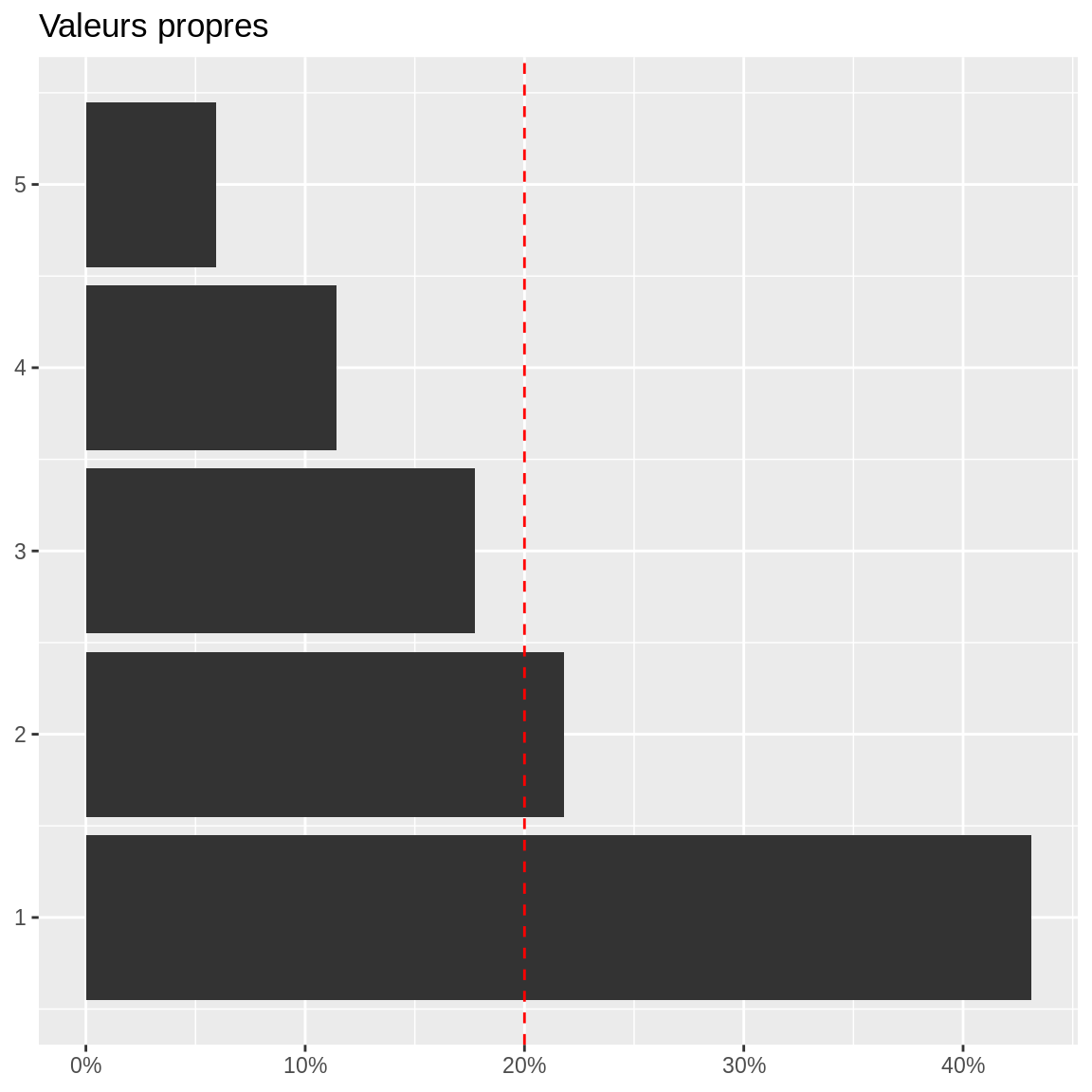
Pour choisir le nombre d’axes à conserver, on peut utiliser plusieurs critères :
- Critère de l’inertie moyenne : on retient les axes qui représentent plus d’inertie que la moyenne (=inertie totale/nombre de variables). Cette inertie vaut 1 dans le cas de l’ACP normée (soit 20% dans notre cas). Cela revient à se dire qu’on ne prend que les nouvelles variables qui portent plus d’inertie que les variables initiales.
- Critère du coude : on retient les premiers axes jusqu’à oberver un “décrochage” dans l’éboulis des valeurs propres. On peut l’objectiver par le calcul des différences secondes entre valeurs propres.
## eigenvalue percentage of variance cumulative percentage of variance
## comp 3 0.85940109 17.1880217 -4.086420
## comp 4 -0.11039646 -2.2079291 -6.294349
## comp 5 0.03891498 0.7782996 -5.516049Ici, le critère de l’inertie moyenne incite à retenir les 2 premiers axes alors que le critère du coude en retiendrait 3 (la dérivée seconde change de signe entre la 3e et 4e valeur propre). Généralement, on prend le critère le plus parcimonieux pour s’épargner du travail ensuite !
4.2.2.5 Interpréter les axes
- Rappel : les axes factoriels sont des combinaisons linéaires des variables initiales. On regarde donc l’importance de ces variables initiales dans les différents axes pour leur donner du sens.
- On doit regarder trois grandeurs pour interpréter (dans cet ordre) :
- Contribution
- Qualité de représentation
- Coordonnée
On visualise le cercle des corrélations. En ACP, qualité et contribution dépendent directement de la coordonnée : il suffit que celle-ci soit élevée pour que la qualité de représentation soit bonne et la contribution forte.
Pour obtenir ce graphique, on utilise la fonction plot.PCA, avec l’argument choix = "var".
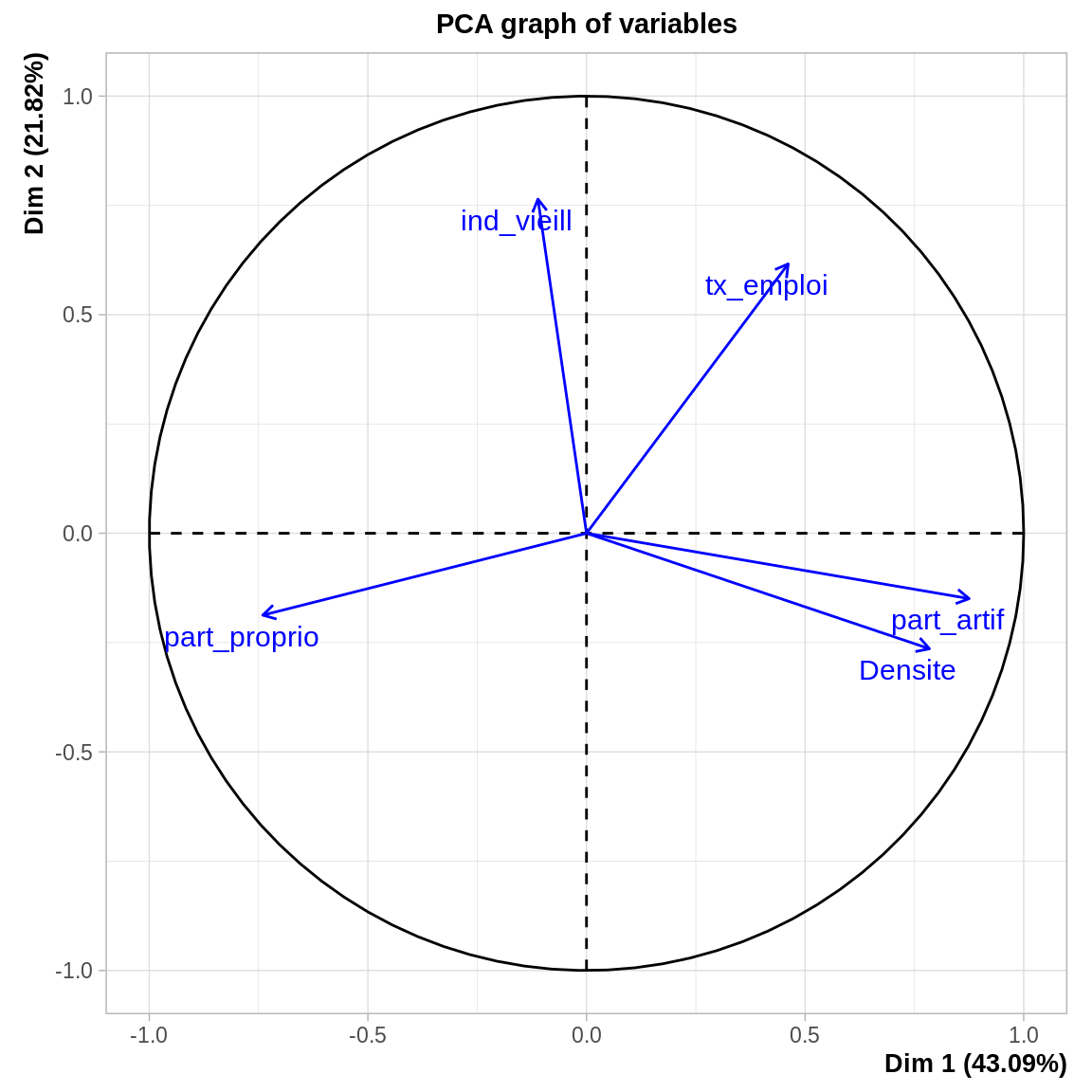
\(\Rightarrow\) on regarde avant tout les variables proches du cercle unité.
A partir de ce cercle (sur le premier plan factoriel), on voit que :
- Les variables part_artif et Densite sont corrélées positivement, et toutes deux négativement à part_proprio.
- La variable ind_vieill est indépendante (~orthogonale) aux trois variables précédentes.
- L’axe 1 porte (~synthétise) 43,1% de l’inertie totale. Il est principalement formé par les variables part_artif, Densite et part_proprio.
- L’axe 2 porte 21,8% de l’inertie. Il est formé par les variables ind_vieill et, dans une moindre mesure, tx_emploi.
On peut interpréter de façon plus fine grâce aux chiffres donnés par la fonction summary.
##
## Call:
## PCA(X = dat, quali.sup = c(5, 7), graph = FALSE)
##
##
## Eigenvalues
## Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
## Variance 2.155 1.091 0.887 0.572 0.296
## % of var. 43.092 21.818 17.731 11.437 5.921
## Cumulative % of var. 43.092 64.910 82.642 94.079 100.000
##
## Individuals (the 10 first)
## Dist Dim.1 ctr cos2 Dim.2 ctr cos2
## 01001 | 0.823 | -0.559 0.000 0.462 | -0.603 0.001 0.538 |
## 01002 | 0.915 | -0.795 0.001 0.756 | -0.407 0.000 0.198 |
## 01004 | 3.847 | 3.393 0.015 0.778 | 0.449 0.001 0.014 |
## 01005 | 0.741 | 0.109 0.000 0.021 | -0.476 0.001 0.413 |
## 01006 | 1.222 | 0.080 0.000 0.004 | -0.055 0.000 0.002 |
## 01007 | 0.623 | 0.219 0.000 0.124 | -0.404 0.000 0.420 |
## 01008 | 0.844 | 0.365 0.000 0.187 | -0.529 0.001 0.392 |
## 01009 | 0.851 | -0.750 0.001 0.778 | -0.263 0.000 0.096 |
## 01010 | 0.701 | 0.060 0.000 0.007 | -0.276 0.000 0.154 |
## 01011 | 0.881 | -0.480 0.000 0.296 | -0.613 0.001 0.483 |
## Dim.3 ctr cos2
## 01001 0.005 0.000 0.000 |
## 01002 0.118 0.000 0.017 |
## 01004 -0.984 0.003 0.065 |
## 01005 -0.351 0.000 0.224 |
## 01006 0.211 0.000 0.030 |
## 01007 -0.254 0.000 0.167 |
## 01008 -0.290 0.000 0.118 |
## 01009 0.232 0.000 0.074 |
## 01010 -0.490 0.001 0.488 |
## 01011 -0.164 0.000 0.034 |
##
## Variables
## Dim.1 ctr cos2 Dim.2 ctr cos2 Dim.3
## Densite | 0.784 28.554 0.615 | -0.264 6.394 0.070 | 0.392
## tx_emploi | 0.461 9.877 0.213 | 0.616 34.798 0.380 | -0.519
## part_artif | 0.875 35.549 0.766 | -0.149 2.049 0.022 | 0.165
## part_proprio | -0.740 25.447 0.548 | -0.187 3.215 0.035 | 0.192
## ind_vieill | -0.111 0.573 0.012 | 0.764 53.545 0.584 | 0.633
## ctr cos2
## Densite 17.301 0.153 |
## tx_emploi 30.330 0.269 |
## part_artif 3.070 0.027 |
## part_proprio 4.152 0.037 |
## ind_vieill 45.146 0.400 |
##
## Supplementary categories
## Dist Dim.1 cos2 v.test Dim.2 cos2
## 0 - Absence de PPRN | 0.243 | -0.235 0.932 -44.179 | 0.003 0.000
## 1 - PPRN prescrit | 0.399 | 0.365 0.836 12.756 | -0.112 0.078
## 2 - PPRN approuvé | 0.543 | 0.523 0.929 40.018 | 0.020 0.001
## Agenda21 0 | 0.052 | -0.048 0.829 -17.414 | 0.009 0.029
## Agenda21 1 | 0.412 | 0.375 0.829 17.414 | -0.070 0.029
## v.test Dim.3 cos2 v.test
## 0 - Absence de PPRN 0.916 | 0.024 0.009 6.937 |
## 1 - PPRN prescrit -5.482 | -0.021 0.003 -1.145 |
## 2 - PPRN approuvé 2.163 | -0.057 0.011 -6.775 |
## Agenda21 0 4.545 | -0.015 0.083 -8.598 |
## Agenda21 1 -4.545 | 0.119 0.083 8.598 |La fonction dimdesc donne les variables les plus liées à chacun des axes.
## $Dim.1
##
## Link between the variable and the continuous variables (R-square)
## =================================================================================
## correlation p.value n
## part_artif 0.8751772 0.000000e+00 36510
## Densite 0.7843627 0.000000e+00 36510
## tx_emploi 0.4613266 0.000000e+00 36510
## ind_vieill -0.1111117 1.236263e-100 36510
## part_proprio -0.7404659 0.000000e+00 36510
##
## Link between the variable and the categorical variable (1-way anova)
## =============================================
## R2 p.value
## PPRN 0.054080975 0.000000e+00
## agd21 0.008306086 3.445294e-68
##
## Link between variable and the categories of the categorical variables
## ================================================================
## Estimate p.value
## PPRN=2 - PPRN approuvé 0.3055307 0.000000e+00
## agd21=Agenda21 1 0.2115150 3.445294e-68
## PPRN=1 - PPRN prescrit 0.1470988 2.415332e-37
## agd21=Agenda21 0 -0.2115150 3.445294e-68
## PPRN=0 - Absence de PPRN -0.4526296 0.000000e+00
##
## $Dim.2
##
## Link between the variable and the continuous variables (R-square)
## =================================================================================
## correlation p.value n
## ind_vieill 0.7642764 0.000000e+00 36510
## tx_emploi 0.6161225 0.000000e+00 36510
## part_artif -0.1494941 1.843625e-181 36510
## part_proprio -0.1872759 2.069053e-285 36510
## Densite -0.2641013 0.000000e+00 36510
##
## Link between the variable and the categorical variable (1-way anova)
## =============================================
## R2 p.value
## PPRN 0.0008706053 1.245555e-07
## agd21 0.0005657106 5.489230e-06
##
## Link between variable and the categories of the categorical variables
## ================================================================
## Estimate p.value
## agd21=Agenda21 0 0.03927776 5.489230e-06
## PPRN=2 - PPRN approuvé 0.04945204 3.051304e-02
## agd21=Agenda21 1 -0.03927776 5.489230e-06
## PPRN=1 - PPRN prescrit -0.08224271 4.171741e-08
##
## $Dim.3
##
## Link between the variable and the continuous variables (R-square)
## =================================================================================
## correlation p.value n
## ind_vieill 0.6326567 0.000000e+00 36510
## Densite 0.3916457 0.000000e+00 36510
## part_proprio 0.1918639 1.002604e-299 36510
## part_artif 0.1649901 4.054263e-221 36510
## tx_emploi -0.5185559 0.000000e+00 36510
##
## Link between the variable and the categorical variable (1-way anova)
## =============================================
## R2 p.value
## agd21 0.002025068 7.791424e-18
## PPRN 0.001395099 8.566069e-12
##
## Link between variable and the categories of the categorical variables
## ================================================================
## Estimate p.value
## agd21=Agenda21 1 0.06699392 7.791424e-18
## PPRN=0 - Absence de PPRN 0.04171611 3.957733e-12
## PPRN=2 - PPRN approuvé -0.03877158 1.223326e-11
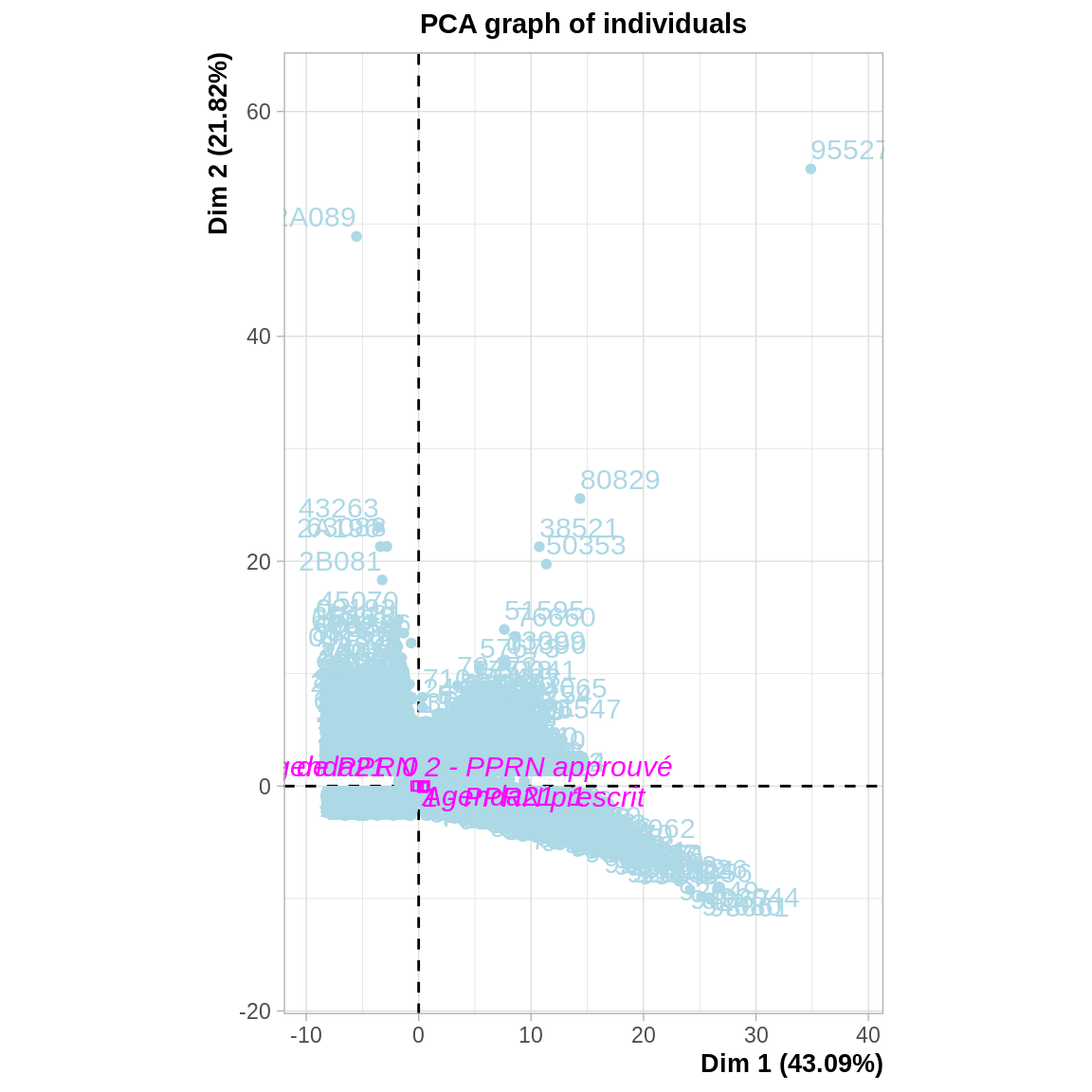
## agd21=Agenda21 0 -0.06699392 7.791424e-18On peut également regarder la projection des individus dans le plan. Ce n’est pas toujours très informatif, ça peut permettre de repérer : - Des groupes d’individus quand il existe des discontinuités. - Des valeurs extrêmes qui peuvent contribuer exagérément aux axes (donc qui nuisent à la représentation du reste des individus).
N’oubliez pas de consulter l’aide des fonctions présentées pour plus d’options.
4.2.2.6 Les variables supplémentaires
Dans toutes les analyses factorielles, on distingue les variables actives, qui participent de la création du nouvel espace vectoriel, des variables supplémentaires, que l’on projette a posteriori sur cet espace, mais qui n’interviennent pas dans la construction des variables synthétiques.
- Elles peuvent être qualitatives ou quantitatives.
- Elles sont projetée sur l’espace des variables (variable continue) ou des individus (qualitative).
- Elles ne rentrent pas dans la matrice qui sert à la définition des axes.
- Elles sont utiles pour voir la corrélation d’une variable (une classe d’individus par exemple) avec toutes les variables simultanément
Dans la fonction PCA, on désigne les variables supplémentaires avec les arguments quali.sup ou quanti.sup ; attention, on les désigne par le numéro de colonne de la variable.
\(\Rightarrow\) Pas lien entre le PPRN et les autres variables : elles se projettent au centre du nuage de points. Les communes disposant d’un PPRN ou d’un Agenda21 n’ont donc pas de caractéristiques particulières.
On peut utiliser le paramètre select pour mettre en évidence certains individus ou variables en fonction de leur contribution ou qualité de représentation. Par exemple select = "contrib 20" permet de n’afficher les étiquettes que des individus qui contribuent le plus aux deux axes représent
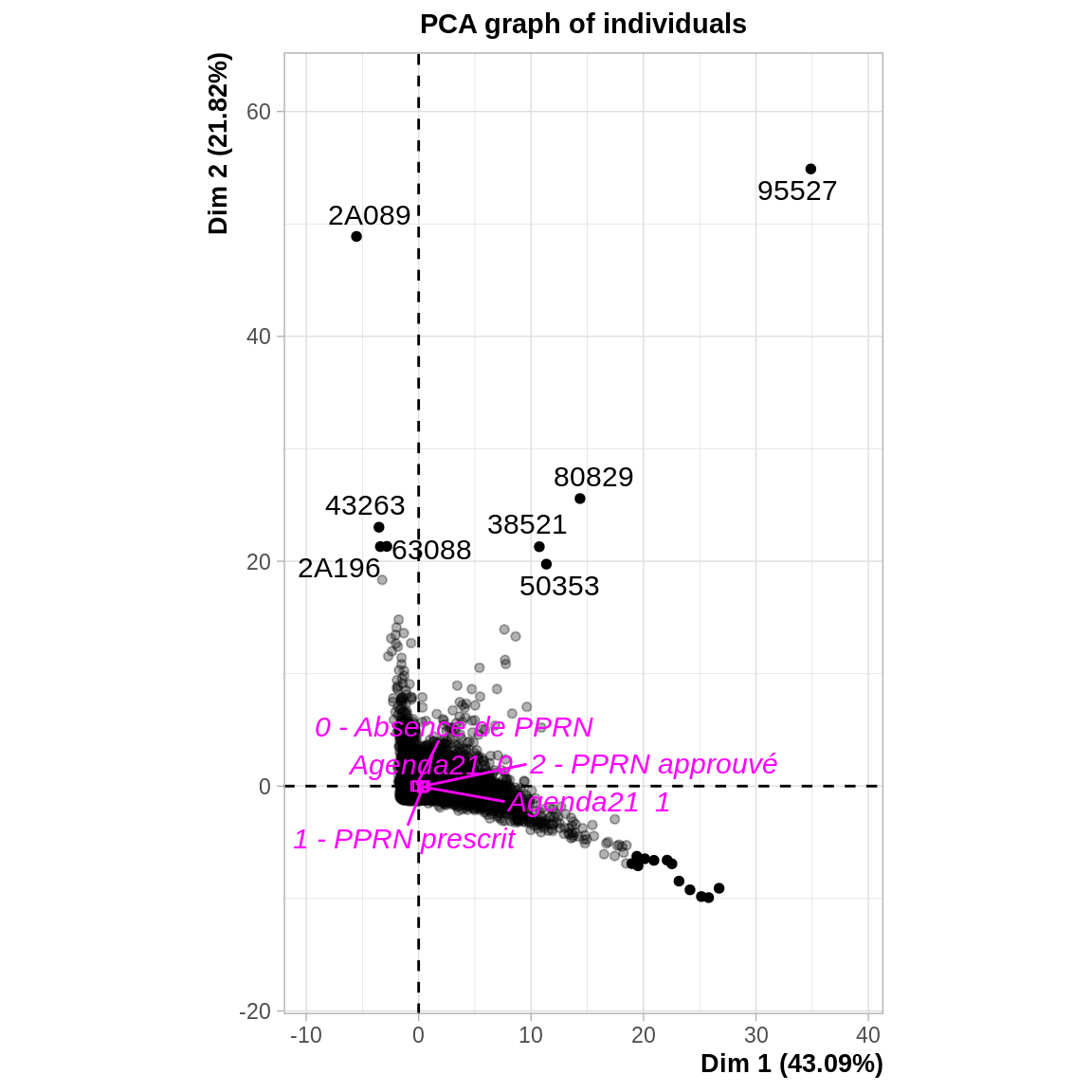
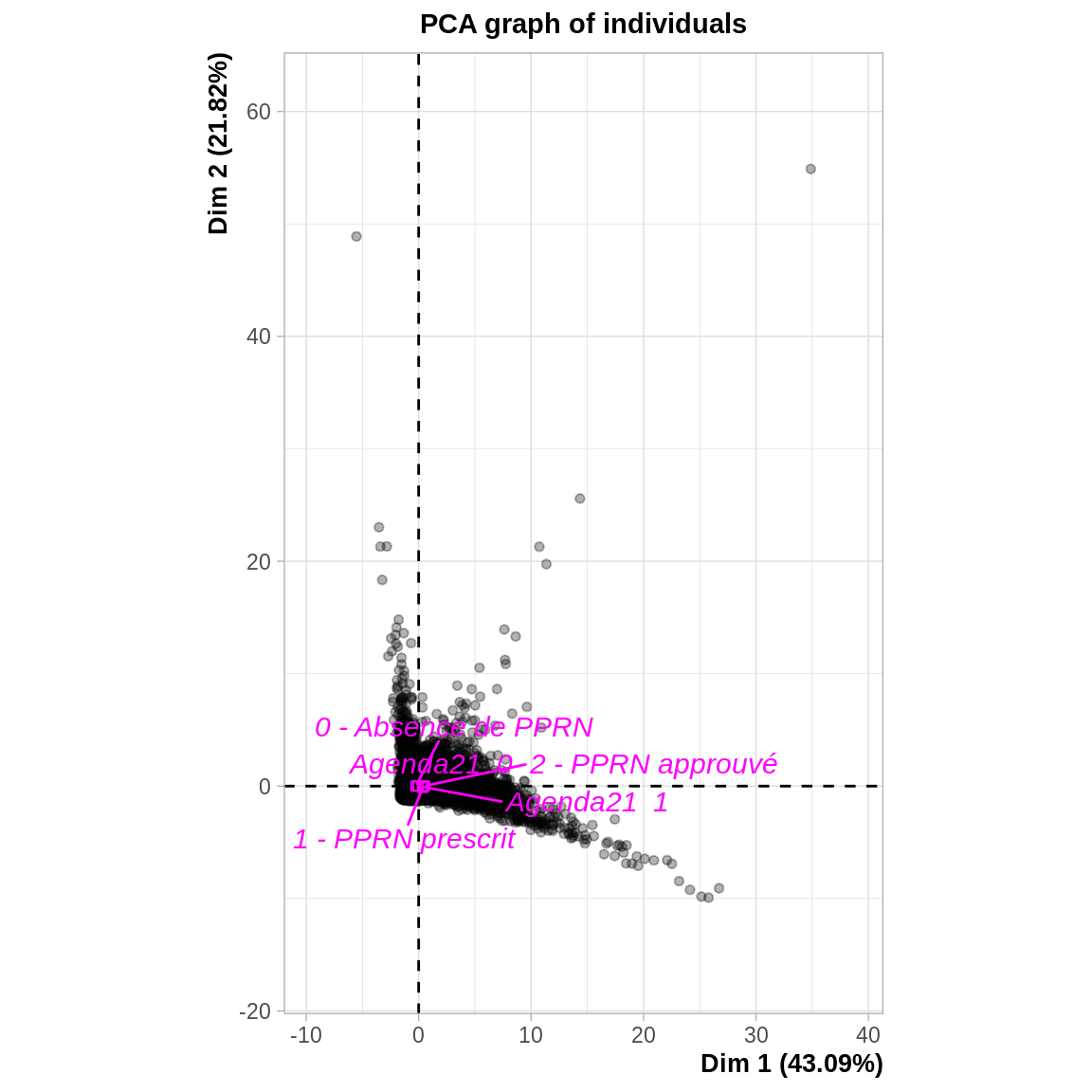
4.2.3 Repérer un effet taille
L’effet taille se recontre assez fréquemment quand on réalise une ACP : il se manifeste par :
- Toutes les variables sont de même signe sur le premier axe factoriel (donc elles sont toutes corrélées positivement entre elles) et celui-ci contient une très grand part de l’inertie.
- Dans ce cas, l’axe 1 constitue un gradient : il permet de classer les individus du plus “petit” au plus “grand”, sur toutes les variables simultanément.
taille <- read.csv2 ("data/Effet_taille.csv", header = TRUE,
encoding = "latin1")
t <- PCA (na.omit (taille[,-c(1,2)]), graph = FALSE)
plot.PCA (t, choix = c ("var"), col.var = "blue")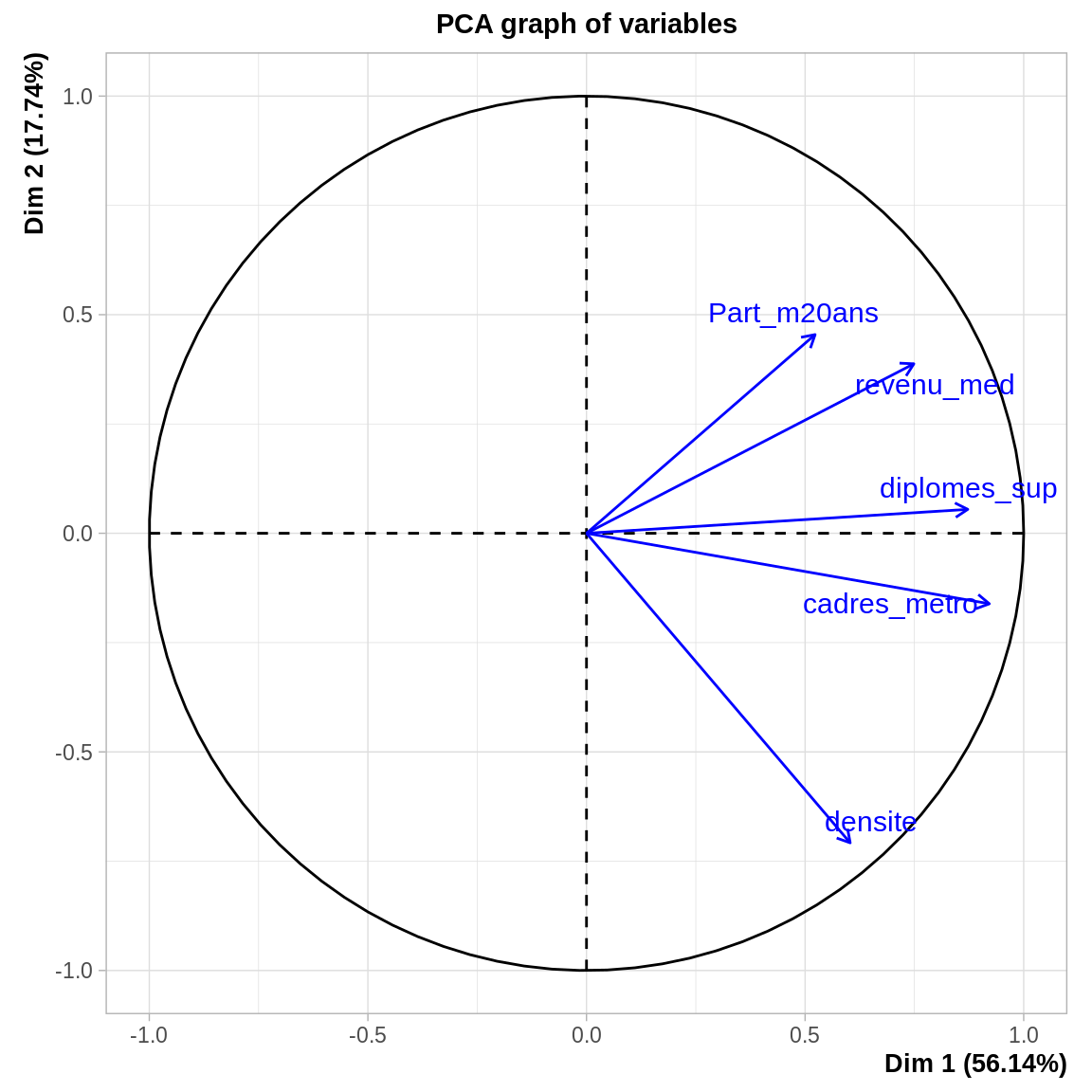
Ce type de configuration peut décevoir quand on ne s’y attend pas. Cependant, il peut y avoir un intérêt car l’axe \(F_1\) synthétise, de manière objective et multidimensionnelle, le lien entre les variables. Ici, revenus, diplômes et statut de cadre sont très liés. Si l’on voulait étudier si ces variables sont corrélées à d’autres caractéristiques des individus, plutôt que de faire 3 analyses semblables, ou de choisir une de ces 3 variables, on pourrait prendre les coordonnées des individus sur \(F_1\) (t$ind$coord[, 1) comme variable de synthèse.
4.3 Exercice
A partir du dataframe iris inclus dans R :
- Explorer rapidement le jeu de données. Quel est le type des variables ?
- Réalisez une ACP sur ce jeu de données.
- Interprétez les résultats obtenus.
- Inclure la variable “Species” dans l’analyse en tant que variable qualitative supplémentaire.
acp.iris <- select (iris, -Species) %>% PCA()
summary (acp.iris)
##
## Call:
## PCA(X = .)
##
##
## Eigenvalues
## Dim.1 Dim.2 Dim.3 Dim.4
## Variance 2.918 0.914 0.147 0.021
## % of var. 72.962 22.851 3.669 0.518
## Cumulative % of var. 72.962 95.813 99.482 100.000
##
## Individuals (the 10 first)
## Dist Dim.1 ctr cos2 Dim.2 ctr cos2 Dim.3
## 1 | 2.319 | -2.265 1.172 0.954 | 0.480 0.168 0.043 | -0.128
## 2 | 2.202 | -2.081 0.989 0.893 | -0.674 0.331 0.094 | -0.235
## 3 | 2.389 | -2.364 1.277 0.979 | -0.342 0.085 0.020 | 0.044
## 4 | 2.378 | -2.299 1.208 0.935 | -0.597 0.260 0.063 | 0.091
## 5 | 2.476 | -2.390 1.305 0.932 | 0.647 0.305 0.068 | 0.016
## 6 | 2.555 | -2.076 0.984 0.660 | 1.489 1.617 0.340 | 0.027
## 7 | 2.468 | -2.444 1.364 0.981 | 0.048 0.002 0.000 | 0.335
## 8 | 2.246 | -2.233 1.139 0.988 | 0.223 0.036 0.010 | -0.089
## 9 | 2.592 | -2.335 1.245 0.812 | -1.115 0.907 0.185 | 0.145
## 10 | 2.249 | -2.184 1.090 0.943 | -0.469 0.160 0.043 | -0.254
## ctr cos2
## 1 0.074 0.003 |
## 2 0.250 0.011 |
## 3 0.009 0.000 |
## 4 0.038 0.001 |
## 5 0.001 0.000 |
## 6 0.003 0.000 |
## 7 0.511 0.018 |
## 8 0.036 0.002 |
## 9 0.096 0.003 |
## 10 0.293 0.013 |
##
## Variables
## Dim.1 ctr cos2 Dim.2 ctr cos2 Dim.3 ctr
## Sepal.Length | 0.890 27.151 0.792 | 0.361 14.244 0.130 | -0.276 51.778
## Sepal.Width | -0.460 7.255 0.212 | 0.883 85.247 0.779 | 0.094 5.972
## Petal.Length | 0.992 33.688 0.983 | 0.023 0.060 0.001 | 0.054 2.020
## Petal.Width | 0.965 31.906 0.931 | 0.064 0.448 0.004 | 0.243 40.230
## cos2
## Sepal.Length 0.076 |
## Sepal.Width 0.009 |
## Petal.Length 0.003 |
## Petal.Width 0.059 |
dimdesc (acp.iris)
## $Dim.1
##
## Link between the variable and the continuous variables (R-square)
## =================================================================================
## correlation p.value n
## Petal.Length 0.9915552 3.369916e-133 150
## Petal.Width 0.9649790 6.609632e-88 150
## Sepal.Length 0.8901688 2.190813e-52 150
## Sepal.Width -0.4601427 3.139724e-09 150
##
## $Dim.2
##
## Link between the variable and the continuous variables (R-square)
## =================================================================================
## correlation p.value n
## Sepal.Width 0.8827163 2.123801e-50 150
## Sepal.Length 0.3608299 5.731933e-06 150
##
## $Dim.3
##
## Link between the variable and the continuous variables (R-square)
## =================================================================================
## correlation p.value n
## Petal.Width 0.2429827 0.0027349555 150
## Sepal.Length -0.2756577 0.0006395628 150
acp.iris <- PCA(iris, quali.sup = 5)