Chapitre 3 Quelques préliminaires
3.1 Vocabulaire
Statistique : un résumé de l’information contenue dans l’ensemble des observation. Par exemple : la somme, la moyenne, l’écart-type, les quantiles…
Description des données : un tableau peut être regardé comme un ensemble de lignes (des individus statistiques) ou comme un ensemble de colonnes (des variables).
\(\rightarrow\) structure du tableau (dataframe) à modifier ? Voir le module 2 sur la préparation des données.
3.2 Données utilisées pour la formation
Nous utiliserons la base Insee de comparaison des territoires. Pour chaque commune, nous disposons d’un certain nombre d’informations, contenues dans les différentes variables (population, naissance, décès, nombre de logements, etc…).
## 'data.frame': 36689 obs. of 29 variables:
## $ CODGEO : chr "01001" "01002" "01004" "01005" ...
## $ LIBGEO : chr "L'Abergement-Clémenciat" "L'Abergement-de-Varey" "Ambérieu-en-Bugey" "Ambérieux-en-Dombes" ...
## $ REG : Factor w/ 17 levels "01","02","03",..: 15 15 15 15 15 15 15 15 15 15 ...
## $ DEP : chr "01" "01" "01" "01" ...
## $ ZAU : chr "120 - Multipolarisée des grandes aires urbaines" "112 - Couronne d'un grand pôle" "112 - Couronne d'un grand pôle" "112 - Couronne d'un grand pôle" ...
## $ ZE : chr "8213 - Villefranche-sur-Saône" "8201 - Ambérieu-en-Bugey" "8201 - Ambérieu-en-Bugey" "8213 - Villefranche-sur-Saône" ...
## $ P14_POP : int 767 239 14022 1627 109 2570 743 338 1142 397 ...
## $ P09_POP : int 787 207 13350 1592 120 2328 660 336 960 352 ...
## $ SUPERF : num 15.95 9.15 24.6 15.92 5.88 ...
## $ NAIS0914 : int 40 16 1051 117 8 175 59 12 56 25 ...
## $ DECE0914 : int 25 7 551 41 3 78 20 11 32 10 ...
## $ P14_MEN : num 306 99.3 6161.1 621.1 52.5 ...
## $ NAISD15 : int 13 5 222 15 2 21 11 2 18 4 ...
## $ DECESD15 : int 5 1 121 7 2 9 3 3 5 0 ...
## $ P14_LOG : num 342.7 161.2 6838.4 661.8 71.5 ...
## $ P14_RP : num 306 99.3 6161.1 621.1 52.5 ...
## $ P14_RSECOCC : num 14 47.3 121.6 10.9 10.9 ...
## $ P14_LOGVAC : num 22.74 14.55 555.64 29.85 8.14 ...
## $ P14_RP_PROP : num 260 84.6 2769 473.3 37.7 ...
## $ NBMENFISC13 : int 297 99 6034 617 47 1014 299 140 431 137 ...
## $ PIMP13 : num NA NA 57.4 NA NA ...
## $ MED13 : num 22130 23213 19554 22388 21872 ...
## $ TP6013 : num NA NA 15.1 NA NA ...
## $ P14_EMPLT : num 85.16 12.81 7452.93 280.57 5.95 ...
## $ P14_EMPLT_SAL: num 52.19 4.95 6743.37 206.38 3.96 ...
## $ P09_EMPLT : num 65.57 17.64 7551.68 286.61 5.29 ...
## $ P14_POP1564 : num 463 141.6 8962.8 1043.1 71.3 ...
## $ P14_CHOM1564 : num 33 9.84 1059.73 66.33 7.93 ...
## $ P14_ACT1564 : num 376 121 6681.9 842.1 57.5 ...Liste des variables :
CODGEO : Code du département suivi du numéro de commune ou du numéro d’arrondissement municipal
LIBGEO : Libellé de la commune ou de l’arrondissement municipal pour Paris, Lyon et Marseille
REG : Région
DEP : Département
ZAU : Classe du zonage en aires urbaines
ZE : Zone d’emploi
P14_POP : Population en 2014
P09_POP : Population en 2009
SUPERF : Superficie (en \(km^2\))
NAIS0914 : Nombre de naissances entre le 01/01/2009 et le 01/01/2014
DECE0914 : Nombre de décès entre le 01/01/2009 et le 01/01/2014
P14_MEN : Nombre de ménages en 2014
NAISD15 : Nombre de naissances domiciliées en 2015
DECESD15 : Nombre de décès domiciliés en 2015
P14_LOG : Nombre de logements en 2014
P14_RP : Nombre de résidences principales en 2014
P14_RSECOCC : Nombre de résidences secondaires et logements occasionnels en 2014
P14_LOGVAC : Nombre de logements vacants en 2014
P14_RP_PROP : Nombre de résidences principales occupées par propriétaires en 2014
NBMENFISC14 : Nombre de ménages fiscaux en 2014
PIMP14 : Part des ménages fiscaux imposés en 2014
MED14 : Médiane du niveau de vie en 2014
TP6014 : Taux de pauvreté en 2014
P14_EMPLT : Nombre d’emplois au lieu de travail en 2014
P15_EMPLT_SAL : Nombre d’emplois salariés au lieu de travail en 2015
P09_EMPLT : Nombre d’emplois au lieu de travail en 2009
P15_POP1564 : Nombre de personnes de 15 à 64 ans en 2015
P15_CHOM1564 : Nombre de chômeurs de 15 à 64 ans en 2015
P15_ACT1564 : Nombre de personnes actives de 15 à 64 ans en 2015
3.3 Variables quantitatives
Une variable quantitative permet de mesurer une grandeur (quantité). Elle peut être :
discrète (un nombre fini de valeurs possibles). Exemple : un nombre de logements
continue (a priori, toutes les valeurs possibles). Exemple : une taille, une surface, un revenu
On peut calculer des statistiques (somme, moyenne, …) sur les variables quantitatives.
Dans R, il s’agit des variables de type numeric. Par exemple :
## [1] "numeric"3.4 Variables qualitatives
3.4.1 Définition
Une variable qualitative indique des caractéristiques qui ne sont pas des quantités. Les différentes valeurs que peut prendre cette variable sont appelées les catégories ou modalités (levels dans R). Elle peut être :
ordonnée (exprimer un ordre). Exemple : “petit - moyen - grand”
non ordonnée. Exemple : une couleur, un groupe sanguin…
Une variable qualitative ne permet pas de faire des calculs (la moyenne d’un groupe sanguin n’a aucun sens).
Dans R, il s’agit des variables factor. Elles peuvent être générée par la fonction factor(). Par exemple :
v <- factor (x = c ("un peu", "beaucoup", "passionnément", "beaucoup",
"un peu", "un peu", "un peu"))
class (v)## [1] "factor"Les modalités de la variable peuvent être obtenues grâce à la fonction levels().
## [1] "beaucoup" "passionnément" "un peu"## .
## beaucoup passionnément un peu
## 2 1 4NB : Ce sont des étiquettes mais la variable est stockée sous forme d’entiers.
## .
## 1 2 3
## 2 1 43.4.2 Manipulation des factor

La manipulation des factor fait intervenir le package forcats, du “méta-package” tidyverse, qui propose de nombreuses fonctions.
Les fonctions de ce package sont reconnaissables à leur préfixe fct_.
On peut trouver des exemples d’utilisation (en français) sur ce blog.
- Dans un dataframe contenant une variable de type
factor, on filtre comme sur une chaîne de caractère :
d <- filter (dat, str_sub (string = ZAU, start = 1, end = 3) != "120")
# ou bien :
d <- filter (dat, ZAU != "111 - Grand pôle (plus de 10 000 emplois)")- A la suite d’une opération de sélection des parmi les lignes, certains
levelspeuvent disparaître. Ils seront toutefois toujours présents dans la liste des modalités de la variables. La fonctionfct_drop(), appliquée sur un vecteur, permet de se débarasser des modalités désormais inutilisées.
## NULL## [1] "112 - Couronne d'un grand pôle"
## [2] "120 - Multipolarisée des grandes aires urbaines"
## [3] "211 - Moyen pôle (5 000 à 10 000 emplois)"
## [4] "212 - Couronne d'un moyen pôle"
## [5] "221 - Petit pôle (de 1 500 à 5 000 emplois)"
## [6] "222 - Couronne d'un petit pôle"
## [7] "300 - Autre commune multipolarisée"
## [8] "400 - Commune isolée hors influence des pôles"La modalité a bien été supprimée.
Pour effectuer l’opération sur l’ensemble des variables factor d’un dataframe, il faut utiliser la fonction droplevels() du package base.
- Les fonctions
levels()etfct_recode()permettent de modifier leslevels. La fonctionlevels()renomme toutes les modalités et s’applique sur un vecteur de typefactor.fct_recode()permet de renommer seulement leslevelsvoulus et peut être imbriqué dans unmutate().
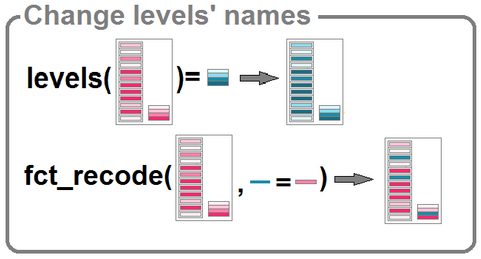
vec_ZAU <- pull (dat, ZAU)
levels(vec_ZAU) <- c("111 - Grand pôle",
"112 - Couronne GP",
"120 - Multipol grandes AU",
"211 - Moyen pôle",
"212 - Couronne MP" ,
"221 - Petit pôle",
"222 - Couronne PP",
"300 - Autre multipol.",
"400 - Commune isolée")
levels (vec_ZAU)## [1] "111 - Grand pôle" "112 - Couronne GP"
## [3] "120 - Multipol grandes AU" "211 - Moyen pôle"
## [5] "212 - Couronne MP" "221 - Petit pôle"
## [7] "222 - Couronne PP" "300 - Autre multipol."
## [9] "400 - Commune isolée"dat$ZAU2 <- vec_ZAU # création de la variable ZAU2 dans le data frame dat
dat <- dat %>%
mutate (DEP2 = fct_recode (DEP, "Ain" = "01", "Aisne" = "02"))- Pour agréger des facteurs et compter le nombre de modalités, on peut se servir de
fct_count():
pull (dat, ZAU2) %>%
fct_recode (urbain = "111 - Grand pôle", urbain = "211 - Moyen pôle",
urbain = "221 - Petit pôle",
periurbain = "112 - Couronne GP", periurbain = "212 - Couronne MP",
periurbain = "120 - Multipol grandes AU", periurbain = "300 - Autre multipol.",
periurbain = "222 - Couronne PP",
rural = "400 - Commune isolée") %>%
fct_count ()## Warning: Unknown levels in `f`: 111 - Grand pôle, 211 - Moyen pôle, 221 - Petit
## pôle, 112 - Couronne GP, 212 - Couronne MP, 120 - Multipol grandes AU, 300 -
## Autre multipol., 222 - Couronne PP, 400 - Commune isolée## # A tibble: 9 × 2
## f n
## <fct> <int>
## 1 111 - Grand pôle (plus de 10 000 emplois) 3285
## 2 112 - Couronne d'un grand pôle 12297
## 3 120 - Multipolarisée des grandes aires urbaines 3962
## 4 211 - Moyen pôle (5 000 à 10 000 emplois) 456
## 5 212 - Couronne d'un moyen pôle 815
## 6 221 - Petit pôle (de 1 500 à 5 000 emplois) 888
## 7 222 - Couronne d'un petit pôle 582
## 8 300 - Autre commune multipolarisée 7021
## 9 400 - Commune isolée hors influence des pôles 7383- Pour modifier l’ordre des facteurs (cela peut être utile en particulier pour les représentations graphiques), il existe plusieurs fonctions :
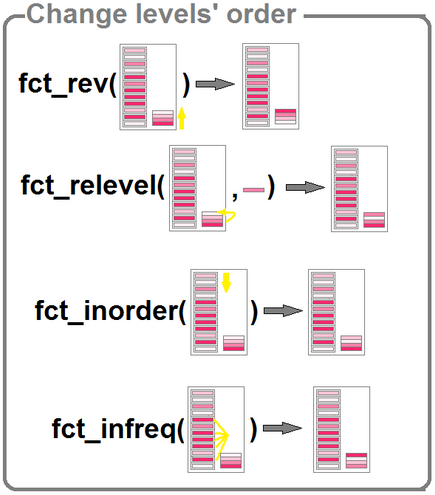
# renverser l'ordre
dat <- dat %>%
mutate (ZAU3 = fct_rev (ZAU2))
# ordonner "à la main"
dat <- dat %>%
mutate (ZAU3 = fct_relevel (ZAU2, "221 - Petit pôle", "111 - Grand pôle"))## Warning: There was 1 warning in `mutate()`.
## ℹ In argument: `ZAU3 = fct_relevel(ZAU2, "221 - Petit pôle", "111 - Grand
## pôle")`.
## Caused by warning:
## ! 2 unknown levels in `f`: 221 - Petit pôle and 111 - Grand pôle