Chapitre 7 Structurer ses tables
7.1 Pourquoi se pencher sur la structuration des tables ?
Pour bien manipuler des données, leur structuration est fondamentale. Il faut bien savoir ce qu’est :
- une ligne de notre table,
- une colonne de notre table.
Sur une table non agrégée (un répertoire, une table d’enquête…), la structuration naturelle est une ligne par observation (un individu, une entreprise…), une colonne par variable (âge, taille…) sur cette observation.
Mais dès qu’on agrège une telle table pour construire des tables structurées par dimensions d’analyse et indicateurs, se pose toujours la question de savoir ce qu’on va considérer comme des dimensions et comme des indicateurs. Le standard tidy data définit 3 principes pour des données propres :
- chaque variable est une colonne,
- chaque observation est une ligne,
- les unités d’observations différentes sont stockées dans des tables différentes.
Le respect de ces règles va nous amener parfois à devoir changer la définition des lignes et colonnes de nos tables en entrée.
Ci-dessous un exemple simple : la population estimée par département et genre en 2019. Ce fichier est un extrait d’un tableur mis à disposition par l’Insee.
## # A tibble: 104 × 20
## dep lib_dep Ensemble_019ans Ensemble_2039ans Ensemble_4059ans
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 01 Ain 167720 150949 179476
## 2 02 Aisne 131435 115046 137405
## 3 03 Allier 67628 61986 87232
## 4 04 Alpes-de-Haute-Prove… 33883 30028 43039
## 5 05 Hautes-Alpes 30518 28633 37887
## 6 06 Alpes-Maritimes 228072 237427 282270
## 7 07 Ardèche 71385 62186 88572
## 8 08 Ardennes 61006 56583 71821
## 9 09 Ariège 31143 28962 41017
## 10 10 Aube 74510 69537 78475
## # ℹ 94 more rows
## # ℹ 15 more variables: Ensemble_6074ans <dbl>, Ensemble_75ansetplus <dbl>,
## # Ensemble_Total <dbl>, Homme_019ans <dbl>, Homme_2039ans <dbl>,
## # Homme_4059ans <dbl>, Homme_6074ans <dbl>, Homme_75ansetplus <dbl>,
## # Homme_Total <dbl>, Femme_019ans <dbl>, Femme_2039ans <dbl>,
## # Femme_4059ans <dbl>, Femme_6074ans <dbl>, Femme_75ansetplus <dbl>,
## # Femme_Total <dbl>En quoi ce fichier n’est pas tidy ?
On retrouve 4 variables dans notre fichier : le territoire, le genre, l’âge et la population, et nos colonnes ne correspondent pas à ces variables.
Quel serait la version tidy de notre fichier ?
## # A tibble: 1,872 × 5
## dep lib_dep genre age nombre_individus
## <chr> <chr> <chr> <chr> <dbl>
## 1 01 Ain Ensemble 019ans 167720
## 2 01 Ain Ensemble 2039ans 150949
## 3 01 Ain Ensemble 4059ans 179476
## 4 01 Ain Ensemble 6074ans 102788
## 5 01 Ain Ensemble 75ansetplus 52755
## 6 01 Ain Ensemble Total 653688
## 7 01 Ain Homme 019ans 86359
## 8 01 Ain Homme 2039ans 75242
## 9 01 Ain Homme 4059ans 89278
## 10 01 Ain Homme 6074ans 49523
## # ℹ 1,862 more rowsComment passer facilement d’un format non tidy à un format tidy ? C’est là qu’intervient le package {tidyr}.
7.2 Les deux fonctions clefs de {tidyr}
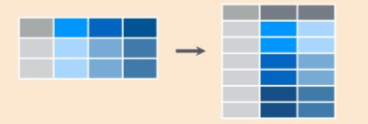
pivot_longer()permet d’empiler plusieurs colonnes (correspondant à des variables quantitatives). Elles sont repérées par création d’une variable qualitative, à partir de leurs noms. Le résultat est une table au format long.
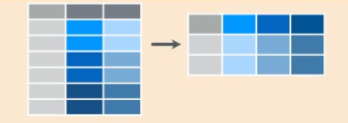
pivot_wider()fait l’inverse. Cette fonction crée autant de colonnes qu’il y a de modalités d’une variable qualitative, en remplissant chacune par le contenu d’une variable numérique. Le résultat est une table au format large.
Pour avoir un aperçu illustré de ces fonctions, voir cette animation
{kind=link}
Reprenons notre table Insee d’estimation de population. Comment faire pour passer cette table dans le format tidy ?
Première étape, retrouvons notre colonne population. Pour cela, il nous faut passer notre table au format long, grâce à pivot_longer().
estim_pop_tidy <- estim_pop %>%
pivot_longer(-c(dep, lib_dep), values_to = "nombre_individus", names_to = "genre_age")
datatable(estim_pop_tidy)Si nous voulions retrouver le format large, nous pourrions utiliser pivot_wider()
estim_pop_nontidy <- estim_pop_tidy %>%
pivot_wider(names_from = genre_age, values_from = nombre_individus)
datatable(estim_pop_nontidy)Nous n’avons pas encore retrouvé nos deux variables genre et age, mais une seule variable mélange les deux.
Pour cela, nous pouvons utiliser separate() du package {tidyr}.
estim_pop_tidy <- estim_pop_tidy %>%
separate(genre_age, sep = "_", into = c("genre", "age"))
datatable(estim_pop_tidy)Mais pivot_longer() permet d’aller encore plus loin en spécifiant sur nos colonnes un moyen de distinguer nos deux variables directement avec l’argument names_sep.
estim_pop_tidy <- estim_pop %>%
pivot_longer(-c(dep, lib_dep), names_sep = "_", names_to = c("genre", "age"),
values_to = "nombre_individus")
datatable(estim_pop_tidy)Et pivot_wider() permet également d’utiliser deux variables pour définir les modalités à convertir en colonnes.
estim_pop_tidy %>%
pivot_wider(names_from = c(genre, age), values_from = nombre_individus) %>%
datatable()Vous retrouverez une introduction complète à {tidyr} dans un article très bien fait de la documentation du package (en anglais).
{tidyr} permet également de transformer des données sous forme de listes en dataframe tidy très simplement.